[추천시스템] 사이킷런을 활용한 추천 시스템 입문
안녕하세요.
이번 포스팅에서는 머신러닝을 활용한 추천 시스템에 대해 알아보도록 하겠습니다.
추천 시스템에 대한 간단한 이론부터 딥러닝 기반의 실습까지 여러 포스팅에 거쳐, 가능한 쉽게❗ 설명해보도록 하겠습니다.
추천 시스템이란?
인스타그램, 유튜브, 넷플릭스 혹은 쿠팡과 같은 커머스까지, 하나쯤은 이용해보신 경험이 있을거라 생각합니다.
인스타그램의 reels, 넷플릭스의 취향저격 콘텐츠… 는 어떻게 내가 관심있는 콘텐츠를 알아내는 걸까요?
사용자가 관심을 가질 만한 아이템을 예측하여 보여주는 기술 이 바로 오늘 저희가 알아볼 추천 시스템입니다.
추천 시스템의 로직
추천의 기본 로직은 유사한 점을 찾아, 유사한 것을 제공하자 에 있습니다.
이를 위해 우리는 ‘유사함’을 계산할 수 있어야 하는데요, 그 방법은 보통 아래의 순서대로 진행됩니다.
1) 범주형, 이산 데이터를 숫자 벡터로 변환 2) 변환된 벡터 간의 유사도 측정 3) 유사도가 높은 아이템을 추천
그렇다면 이러한 벡터 간의 유사도 계산은 어떻게 이루어질까요?
유사도 계산법
유사도 계산 방법 중 가장 잘 알려진 방법은 코사인 유사도(Cosine Similarity) 입니다. 코사인 유사도는 두 벡터 간의 코사인 값(각도)를 이용해 유사도를 측정합니다.
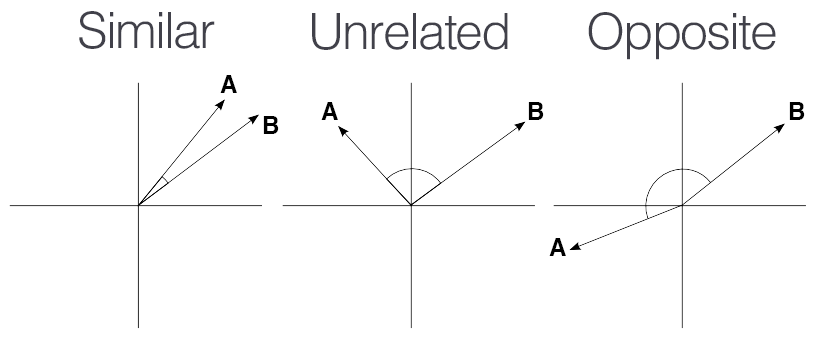
사진의 좌측처럼 방향이 동일한 경우 1에 가까우며, 완전히 동일한 경우 유사도는 1이 됩니다.
가운데 그래프처럼 직교하는 경우 무관함을 의미하며, 코사인 유사도는 0이 됩니다.
마지막으로, 우측 그래프처럼 반대 방향인 경우 -1 에 가까워지며, 완전히 반대인 경우 -1 이 됩니다.
즉, 코사인 유사도는 -1 ~ 1 사이의 값을 가지며, 1에 가까울 수록 서로 더 유사함을 의미합니다.
수식
\[\cos(\theta) =\frac{\mathbf{A}\cdot\mathbf{B}}{\lVert\mathbf{A}\rVert\,\lVert\mathbf{B}\rVert} =\frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2}\,\sqrt{\sum_{i=1}^{n} B_i^2}}\]코사인 유사도의 계산 수식은 위와 같으며, 코드를 통해 직접 계산해보도록 하겠습니다.
코사인 유사도는 numpy를 통해 직접 계산하는 방법과 scikit-learn 의 메서드를 활용하는 방법이 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Numpy
import numpy as np
from numpy import dot
from numpy.linalg import norm
# 임의의 array 생성
t1 = np.array([1, 1, 1])
t2 = np.array([2, 0, 1])
# 코사인 유사도 계산식 정의
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
cos_sim(t1, t2)
scikit-learn 을 통한 유사도 계산은 훨씬 간편합니다.
다만 numpy와 달리 2차원 배열을 input으로 받음을 유의해야 합니다.
1
2
3
4
5
6
7
from sklearn.metrics.pairwise import cosine_similarity
# 입력값으로 2차원 배열을 받음.
t1 = np.array([[1, 1, 1]])
t2 = np.array([[2, 0, 1]])
cosine_similarity(t1,t2)
여기까지 코사인 유사도 계산법을 알아보았습니다. 이어서 이 값을 활용하는 구체적인 방법에 대해 알아보겠습니다.
추천 시스템의 종류
추천 시스템은 최근 연구가 활발히 진행되며 그 종류가 다양해지고 있습니다만, 크게 세 종류로 구분할 수 있습니다.
| 방식 | 설명 |
|---|---|
| 콘텐츠 기반 필터링(Content Based Filtering) | 아이템 특성(장르, 배우 등)을 비교 |
| 협업 필터링(Collaborative Filtering) | 사용자 행동(평점, 시청 이력) 비교 |
| 딥러닝 방식 | 신경망으로 사용자 취향 학습 |
이번 포스팅에서는 위의 두 방식, 콘텐츠 기반 필터링과 협업 필터링을 중심으로 알아보겠습니다.
콘텐츠 기반 필터링
콘텐츠 기반 필터링은 순수하게 아이템 자체의 속성(콘텐츠의 내용)을 기반으로 추천하는 방식입니다.
예를 들어 영화를 콘텐츠 기반 필터링 추천을 할 경우,
- 장르
- 배우
- 감독
등의 정보가 각각의 feature가 되어 유사도 측정에 활용됩니다.
협업 필터링
협업 필터링은 과거의 사용자 행동 양식(User Behavior) 데이터를 기반으로 추천하는 방식입니다.
콘텐츠 기반 필터링과 달리, 콘텐츠가 가진 속성뿐만 아니라 사용자의 선호도도 반영하여 추천합니다.
이러한 협업 필터링은 무엇을 기준으로 유사도를 계산하는지에 따라 다음의 표처럼 구분됩니다.
| 방식 | 예시 문구 |
|---|---|
| 사용자 기반(User-Based) | “당신과 비슷한 취향의 사람들이 본 영화” |
| 아이템 기반(Item-Based) | “이 영화를 본 사람들이 같이 본 영화” |
| 잠재요인(Latent Factor) | “취향을 잠재 요인으로 학습해 추천” |
최근에는 잠재요인 분석 사례가 많아지는 추세이며, 넷플릭스 또한 이를 활용하여 큰 성공을 거둔 것으로 알려져 있습니다.
직관적으로 이해되는 User, Item based 협업 필터링과 달리, 잠재 요인은 잘 와닿지가 않습니다. 이를 더 알아보도록 하겠습니다.
잠재 요인 협업 필터링
| 사용자 | 액션 영화 | 코미디 영화 |
|---|---|---|
| A | ⭐⭐⭐ | ⭐ |
| B | ⭐ | ⭐⭐ |
| C | ⭐⭐⭐ | ⭐ |
| D | ⭐⭐⭐⭐ | ⭐⭐⭐ |
위 표는 액션 영화와 코미디 영화에 대해 각 사용자들이 남긴 평점입니다. 여기서 우리는 무엇을 알 수 있을까요?
우선 A, C 는 각 장르에 대해 동일한 평점을 주었습니다. 두 사용자의 취향이 동일하다고 추론해볼 수 있습니다.
또한 B 는 A, C와 달리 액션 영화에 1점, 코미디에 2점이라는 낮은 점수를 주었습니다. 액션, 코미디 모두 관심이 없나봅니다.
위처럼 실제 기록된 데이터는 ⭐밖에 없지만, 우리는 A, C의 취향이 유사하고 B 와 D 의 취향이 어떤지 추론할 수 있었습니다.
즉, 사용자는 단순히 평점을 남기지만 그 이면에는 ‘어떤 장르를 좋아하는지’에 대한 숨겨진 취향 데이터를 남기고 있는 것입니다.
그리고 이러한 숨겨진 취향을 잠재 요인이라고 하며, 위처럼 평점 행렬을 분해하고 분석하는 방법이 행렬 인수분해 입니다.
행렬 인수분해 알고리즘으로는 다양한 기법들이 있는데, 이번 포스팅에서는 SVD(Singular Vector Decomposition)를 중심으로 설명하겠습니다.
SVD
SVD(Singular Vector Decomposition)는 ‘특이값 분해’로, m x n 형태의 행렬 A를 다음과 같은 형태로 분해하여 나타내는 기법입니다.
수식의 기호에 대해 설명하자면 아래와 같습니다.
- $U$: 왼쪽 특이벡터(orthonormal)들을 열로 모은 직교 행렬.
m x m형태이며, 행렬A의 column space에 기반하고 있음. - $\Sigma$: 특이값(diagonal) 행렬.
m x n형태이며, 대각선에 특이값들이 배치된 구조. - $V$: 오른쪽 특이벡터(orthonormal)들을 열로 모은 직교 행렬.
n x n형태이며, 행렬A의 row space에 기반하고 있음. - $V^T$: 행렬 V의 전치(transpose) 행렬. V와 같은
n x n형태이며, V^-1(역행렬)과 동일.
note: 직교(orthogonal) 행렬이란 다음의 성질을 만족하는 행렬. U가 직교 행렬이라고 한다면, $UU^T = U^T U = I$ 를 만족함. 이에 따라 $U^{-1} = U^T$ 도 만족

이처럼 SVD 기법을 수식으로만 봤을 땐 뭔가.. 잡힐듯 말듯 이해하기 어려운데요, 그림을 통해 직관적으로 보면 이해가 쉽습니다.
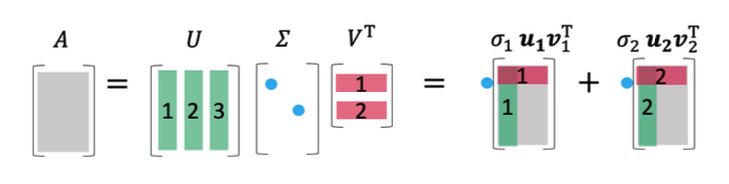
- 녹색 벡터: column feature
- 붉은 벡터: row feature
- $\Sigma$: “얼마나 중요한 축인지?”를 나나태는 세기 혹은 강도. (특이값 $\sigma_i$ 가 클수록 중요한 feature)
쉽게 말해, 행렬 A는 중요한 feature vector들을 중요도($\sigma_i$)만큼 더한 조합 입니다.
그리고 이러한 A에서 상위 k개의 주요 feature만 잘라서 사용하는 것이 Truncated SVD이며, 추천 시스템에서 많이 쓰이는 행렬 인수분해 알고리즘입니다.
이러한 SVD는 Numpy를 통해 손쉽게 계산해볼 수 있습니다.
1
2
3
4
5
6
7
8
import numpy as np
from numpy.linalg import svd
# 랜덤 행렬 A 생성
np.random.seed(30)
A = np.random.randint(0, 100, size=(4, 4))
svd(A)
위 코드를 실행하면, U, S, VT 값이 하나의 array 형태로 출력되기 때문에, 추가적인 처리를 진행 합니다.
1
2
3
4
5
U, Sigma, VT = svd(A)
print('U matrix: {}\n'.format(U.shape),U)
print('Sigma: {}\n'.format(Sigma.shape),Sigma)
print('V Transpose matrix: {}\n'.format(VT.shape),VT)
이처럼 우리는 Numpy를 통해 손쉽게 SVD를 계산할 수 있습니다. 추천 시스템도 별 거 아니죠?
라고 생각할 수 있습니다만, 실상은 그렇지 않습니다.
Numpy를 통한 SVD 계산은 행렬이 너무 커서 계산량이 많아, 성능이 떨어지기 때문입니다.
그래서 잠재 요인 협업 필터링을 진행할 때에는, 이런 SVD의 아이디어를 차용한 Matrix Factorization 을 이용합니다.
((작성중…))