[시계열 분석] 모델링과 평가 (2)
안녕하세요!
지난 포스팅에서는 ARIMA 그리고 SARIMA 모델을 활용한 모델링과 예측까지의 과정을 다루었습니다. ARIMA 란?
이번 글에서는 시계열의 또 다른 중요한 특성인 변동성(Volatility), 즉 분산의 시각적 변화를 다루는 ARCH/GARCH 모델과, 이후 발전된 딥러닝 기반 시계열 예측 접근법을 알아보도록 하겠습니다.
이번에는 AirPassengers 대신 arch 패키지에서 제공하는 예제 데이터를 사용할 예정입니다.
ARCH, GARCH
기본 개념
시계열 데이터 분석 모델 중 ARIMA는 평균을 예측하는 방법입니다.
최적화된 분석을 위해 분산을 없애고 정성 데이터로 변환한다고 해도, 평균 예측만으로는 변동성의 시간적 변화를 설명하는데 한계가 있습니다.
이를 개선하기 위해 등장한 아이디어가 ARCH 그리고 GARCH 입니다.
본 모델은 오차의 분산을 과거 충격과 과거 분산의 함수로 두자는 아이디어에 기초하고 있습니다.
ARCH (Autoregressive Conditional Heteroskedasticity)
ARCH는 과거 충격의 크기(오차의 제곱)으로 현재의 조건부 분산을 설명합니다.
\[\epsilon_t = \sigma_t z_t,\quad z_t\sim \mathcal{N}(0,1),\qquad \sigma_t^2 = \alpha_0 + \alpha_1\epsilon_{t-1}^2 + \cdots + \alpha_q\epsilon_{t-q}^2\]기호 설명
- $\epsilon_t$: 시점 $t$의 예측 오차(혁신, shock)
- $\sigma_t^2$: 시점 $t$의 조건부 분산 (변동성의 제곱)
- $\sigma_t$: 시점 $t$의 조건부 표준편차(변동성)
- $z_t$: 백색잡음. 보통 $z_t\sim\mathcal{N}(0,1)$ 가정(정규), 실무는 t-분포 등 대체 가능
- $\alpha_0$ (또는 $\omega$): 기저(base) 변동성 수준 (항상 양수)
- $\alpha_i$: ARCH 효과 — 과거 충격 $\epsilon_{t-i}^2$가 현재 분산에 미치는 영향(민감도)
간단히 위 수식을 해석하자면, 최근 큰 변동($\epsilon^2$) 이 있으면 당분간 변동성이 커집니다.
급격한 변동성에 대해서는 민감하게 반응하지만, 지속적인 변동에 대해서는 표현이 제한적이라는 특징이 있습니다.
알파에 대해서는 GARCH 수식에서 베타와 함께 설명하겠습니다.
GARCH (Generalized ARCH)
GARCH(p,q)
\(\sigma_t^2 = \alpha_0 + \sum_{i=1}^q \alpha_i\epsilon_{t-i}^2 + \sum_{j=1}^p \beta_j\sigma_{t-j}^2\)
기호 설명
- $\beta_j$: GARCH 효과 — 과거 분산 $\sigma_{t-j}^2$의 지속성
- $p,q$: GARCH의 차수 — $p$: 과거 분산 차수, $q$: 과거 충격 차수
$\alpha_1$ 은 충격 민감도를, $\beta_1$ 은 지속성을 의미합니다. 지속적인 변동에 대해 제한적이었던 ARCH를 개선한 모델입니다.
$\alpha_1+\beta_1$ 이 1에 가까울수록 높은 변동성이 천천히 줄어들어, 지속성이 오릅니다.
GARCH 모델은 현실적인 변동성 군집현상을 재현하는데 유리하며, 확장 모델로 EGARCH, GJR-GARCH 등이 있습니다.
변동성 군집현상(Volatility clustering)이란, 변동성이 한 번 커지면 변동성이 커진 상황이 한동안 지속될 가능성이 높다는 이론 — 한경 경제용어사전, (접속일: 2025-10-15), https://dic.hankyung.com/economy/view/?seq=9783
정리하자면,
- 급격한 변동에 대한 반응만 반응 > ARCH(q)
- 지속성까지 반영 > GARCH(1,1)부터 시작 (최소한의 매개변수로 실험 시작)
- 평균(Conditional Mean)까지 반영하고자 할 경우 > (S)ARIMA와 결합
파라미터
위에서 약술한 알파와 베타를 포함하여 GARCH 의 파라미터는 아래의 표처럼 정리할 수 있습니다:
| 기호/이름 | 의미 | 해석 포인트 |
|---|---|---|
$ \omega $ (omega) | 기저(base) 분산 수준 | $ \omega>0 $. 장기분산의 분모에 들어감 |
$ \alpha_i $ (alpha[i]) | ARCH 효과: 과거 충격 $ \epsilon_{t-i}^2 $ 영향 | 급격한 변동에 대한 즉각 반응 크기 |
$ \beta_j $ (beta[j]) | GARCH 효과: 과거 분산 $ \sigma_{t-j}^2 $ 영향 | 변동성의 지속성 |
| $ p, q $ | GARCH 차수: $ p $=과거 분산, $ q $=과거 충격 | 보통 GARCH(1,1) 로 시작 |
그러면 이어서 코드를 통해 직접 모델을 구동해보도록 하겠습니다 😊
데이터셋: S&P 500(ARCH 제공)
우선 데이터셋을 로드하고, 모델 분석을 위해 사전 작업을 진행하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import datetime as dt
import matplotlib.pyplot as plt
import arch.data.sp500
# arch module 없을 경우
# pip install arch
st = dt.datetime(2002, 1, 1) # start date
en = dt.datetime(2022, 1, 1) # end date
# 예제 데이터 로드
data = arch.data.sp500.load()
market = data['Adj Close'] # 종가 활용
# 단순 수익률(%)로 변환
returns = 100 * market.pct_change().dropna()
ax = returns.plot()
xlim = ax.set_xlim(returns.index.min(), returns.index.max())
plt.show()
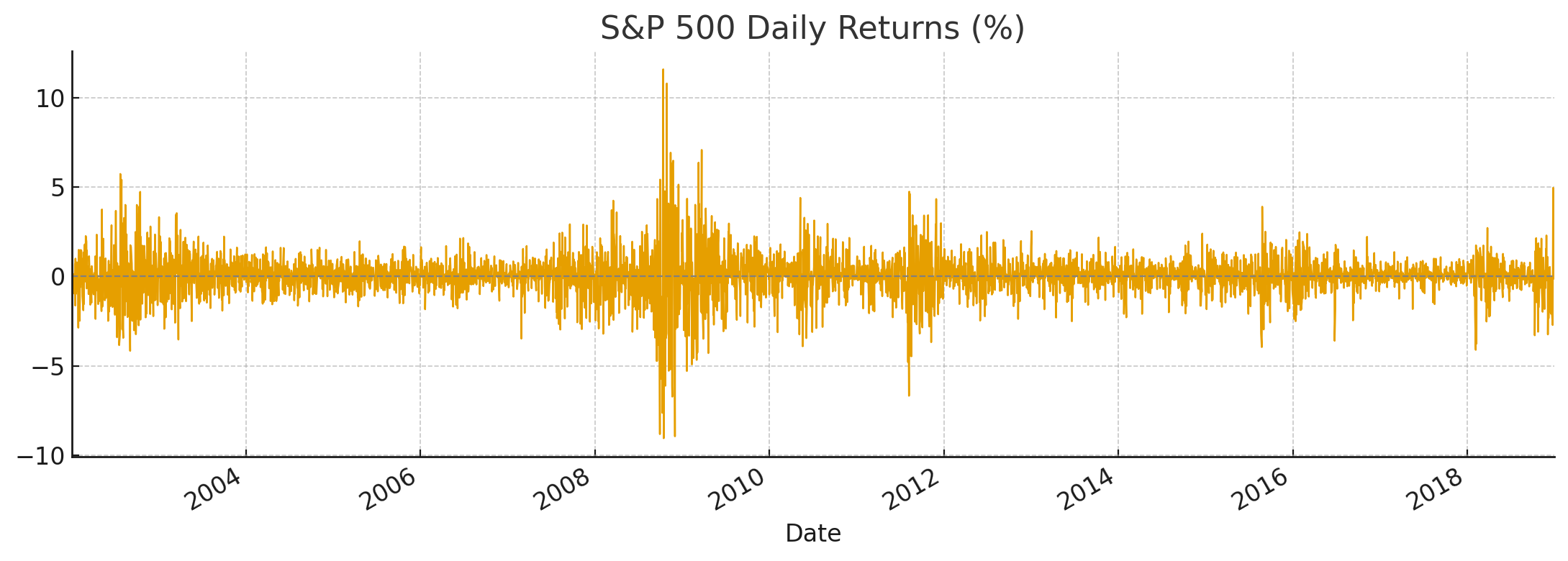
사진을 보면 특정 시기에 큰 분산이 몰려있고, 한동안 잔잔함을 알 수 있는데, 이것이 변동성 군집현상의 신호라고 할 수 있습니다.
또한, 꼬리가 두껍고 비대칭적입니다. 이 시그널들을 통해 데이터에 조건부 이분산성이 있다고 추론해볼 수 있습니다.
조건부 이분산성(Conditional Heteroskedasticity)이란, 오차항의 분산이 특정 기간에 따라 변화하는 현상
모델 학습
이분산성을 의심하고 있으므로 GARCH를 통해 모델 학습을 진행해봅니다.
1
2
3
4
5
6
7
8
9
10
11
from arch import arch_model
am = arch_model(
returns,
mean = 'Constant', # 평균식(ARIMA를 쓰기도)
vol = 'GARCH', # 분산식
p = 1, q = 1, # GARCH(1,1)
dist = 't' # 금융데이터의 경우 주로 t-분포
)
res = am.fit(update_freq = 5) # update_freq: 로그 출력
print(res.summary())
결과 해석
그대로 코드를 따라오셨다면,
다음과 같은 table이 출력됩니다. (결과가 다를 수 있습니다)
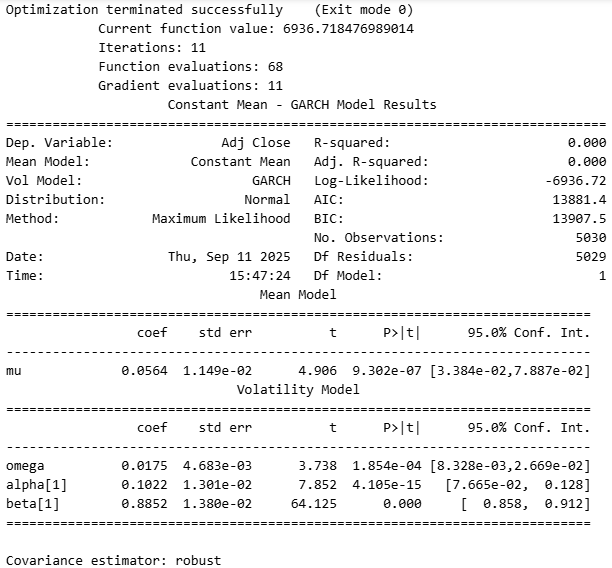
테이블을 하나씩 뜯어 해석해보면 다음처럼 정리할 수 있습니다.
- Mean Model
- Constant Mean: 일평균 수익률 μ 는 0.056% 로, p-value가 작아 유의함
- Volatility Model (GARCH(1,1))
- omega : 기저 변동성 수준을 의미하며, 0.0175 로 양수이며, 유의함.
- $\alpha_1$ : 최근 급등락 충격에 대한 즉각 반응 크기이며, 0.1022 로 유의함.
- $\beta_1$ : 변동성의 지속성이 0.8852 로 유의함.
- $\alpha_1+\beta_1$ : 약 0.9874 로, 매우 높은 지속성을 보임. 즉, 충격이 천천히 소멸함.
기타 딥러닝 모델
지금까지 알아본 ARIMA, ARCH 등의 전통 모형은 해석성과 데이터의 효율성에서 강점을 지니고 있습니다.
데이터의 규모가 작은 경우, 여전히 해당 모델들이 Kaggle 경연에서도 좋은 점수를 받기도 합니다.
그러나, 데이터의 규모가 커져 비선형 패턴 혹은 복잡한 상호작용을 갖는 데이터의 경우, 딥러닝 모델이 두각을 드러냅니다.
딥러닝 모델에 대해서는 후일 별도 포스팅에서 다룰 예정이니, 여기선 다양한 모델들에 대해 간략히 알아보고 마치겠습니다.
- LSTM/GRU: 긴 시퀀스의 장기 의존성을 학습합니다. 계절, 추세, 비선형이 얽힌 데이터에서 안정적이며, feature와 데이터가 많을 때 유용합니다.
- Transformer: 어텐션 기반 병렬 학습으로, gpt의 기본 모델입니다. 장기 예측에 강하지만 파라미터가 많고 메모리 비용이 커서, 적절한 정규화 및 조기 종료 설정이 필요합니다.
위처럼 딥러닝 모델은 sample과 feature가 큰 데이터이거나, 비선형 데이터로 의심되는 경우 선택하면 좋습니다.
딥러닝 모델과 전통 모델을 동시에 활용하는 하이브리드 전략도 유용한 편입니다.
이렇게 시계열 데이터 분석 모델에 대해 다양하게 알아보았습니다.
다음 포스팅에서는 시계열 데이터를 통한 예측이 아닌 시계열 데이터 비교에 대해 알아보겠습니다.
미국 내 전력 소모 데이터를 바탕으로, 시계열 데이터를 비교하고 분류하는 작은 프로젝트를 진행해보겠습니다.
감사합니다. 😊