[시계열 분석] 모델링과 평가
지난 포스팅에서는 시계열 데이터의 정상성(Stationarity)과 전처리 과정을 다루었습니다.
이번 글에서는 이렇게 정제된 데이터를 활용하여 실제로 예측에 많이 쓰이는 ARIMA 계열 모델과 ARCH/GARCH 모델, 그리고 최신 딥러닝 기반 접근법까지 간단히 살펴보겠습니다.
지난 포스팅에서 다룬 Airpassengers data를 그대로 사용합니다. 아직 읽어보지 않으셨다면?
ARIMA & SARIMA
기본 개념
ARIMA는 시계열 분석에서 가장 오래되고 널리 쓰이는 예측 모델 중 하나입니다. 2017년 Transformer와 같은 딥러닝 모델이 개발되었지만, 여전히 데이터가 적은 경우 ARIMA는 좋은 성능을 보여주고 있습니다. 비록 고전적인 모델이지만 시계열 분석의 핵심적인 인사이트를 얻어갈 수 있으므로, 확실히 정리하고 딥러닝 모델로 넘어가면 좋습니다.
ARIMA의 핵심은 과거 데이터와 오차항을 활용해 미래 값을 예측한다는 것입니다.
ARIMA 구성 요소
AR (AutoRegressive, p, 자기회귀)
\[y_t = c + \phi_1 y_{t-1} + \phi_2 y_{t-2} + \dots + \epsilon_t\]
현재 값이 과거 값들의 선형 결합으로 표현됩니다.비유하자면, 내가 오늘 공부할 시간을 ‘어제,그제 공부량’으로 추측하는 것을 의미합니다.
MA (Moving Average, q, 이동평균)
\[y_t = c + \epsilon_t + \theta_1 \epsilon_{t-1} + \theta_2 \epsilon_{t-2} + \dots + \theta_q \epsilon_{t-q}\]
현재 값이 과거 오차항의 선형 결합으로 설명됩니다. 과거의 오차가 현재에 영향을 미친다고 가정합니다.비유하자면, 내가 오늘 공부할 시간을 ‘어제 얼마나 계획에서 벗어났는지’로 추측하는 것을 의미합니다.
I (Integrated, 차분)
데이터가 정상성을 만족하도록 차분(d)을 취해 추세를 제거합니다.ARIMA(p,d,q)
AR(p) + I(d) + MA(q)를 결합한 모델로, 실제 시계열 데이터의 추세, 자기상관, 잡음을 동시에 다룰 수 있습니다.
즉, 위 세 가지(AR, I, MA)를 모두 고려하여 단기적, 장기적 패턴을 동시에 설명하는 모델이 ARIMA 라고 할 수 있겠습니다.
SARIMA: 계절성을 포함한 확장형 ARIMA
하지만 현실의 데이터에는 계절적 패턴(Seasonality)이 존재하는 경우가 다반사입니다.
이번 포스팅에서도 이어서 다룰 항공 승객 수 데이터를 포함하여, 월별 판매량, 전력 소비량 등, 많은 데이터가 일정한 주기를 가지고 반복되는 특성이 있습니다.
이때 단순 ARIMA로는 n개월마다 반복되는 구조를 반영하기 어렵습니다.
그래서 등장한 것이 SARIMA(Seasonal ARIMA) 입니다.
SARIMA는 ARIMA의 확장형으로, 비계절 요인 외에 계절 요인까지 함께 반영합니다. 파라미터는 다음과 같습니다:
- (p,d,q): 비계절 ARIMA의 차수
- (P,D,Q): 계절 요인의 AR, I, MA 차수
- m: 계절 주기 (예: 12 = 1년 주기)
예를 들어 AirPassengers 데이터는 월별 데이터이고 1년 주기로 반복되는 경향이 있으므로 m = 12 로 설정합니다.
파라미터의 의미
ARIMA 의 대표적인 파라미터는 아래와 같습니다. SARIMA는 여기에 계절형 파라미터가 추가됩니다.
보다 상세한 파라미터 정보는 우측의 하이퍼링크를 통해 확인하실 수 있습니다. 공식 문서
| 구분 | 의미 | 설명 |
|---|---|---|
p | 비계절 AR 차수 | 과거 몇 시점의 데이터까지 참고할지 |
d | 차분 차수 | 몇 번 차분해야 정상성이 확보되는지 |
q | 비계절 MA 차수 | 과거 몇 시점의 오차항을 고려할지 |
P | 계절 AR 차수 | 계절적 자기회귀 영향 |
D | 계절 차분 횟수 | 주기적 추세 제거 |
Q | 계절 MA 차수 | 계절적 이동평균 영향 |
m | 계절 주기 | 주기의 길이 (월별 = 12) |
즉,
p는 “과거 데이터 기억 길이”d는 “추세 제거 횟수”q는 “오차 메모리 길이”m은 “패턴이 반복되는 주기”
라고 이해하면 쉽습니다.
파라미터의 추정 - ACF, PCAF
그렇다면 위의 파라미터는 어떤 방식으로 구할 수 있을까요?
ARIMA의 파라미터는 Auto_ARIMA를 통해 자동으로 최적값을 출력하는 방법도 있지만, 전통적인 방법으로는 Box-Jenkins 방법이 있습니다.
이는 ACF, PCAF 함수를 보며 초기 파라미터 p,q를 적합시키는 방법입니다. 그러면 Airpassengers 데이터를 통해 분석해보겠습니다.
Notes: ACF 와 PACF 란?
| 구분 | ACF | PACF |
|---|---|---|
| 의미 | 전체 시계열의 시차 간 상관관계 | 중간 영향을 제거한 순수한 시차 간 상관관계 |
| 해석 | 전체적인 패턴(주기성, 추세)을 파악 | 특정 시차의 직접 영향 확인 |
| 사용 목적 | MA(q) 추정 | AR(p) 추정 |
👉 ACF는 전체적인 자기상관 구조를 파악하고, PACF는 직접적인 자기상관(순수한 영향)을 측정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import pandas as pd
import numpy as np
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import matplotlib.pyplot as plt
ap = pd.read_csv("airline-passengers.csv")
ap.drop('Month', axis = 1, inplace = True)
# 로그 변환 + 차분
log_transformed = np.log(ap)
diffed = log_transformed.diff().dropna()
# SARIMA 분석을 위해 계절 차분은 진행하지 않았습니다
# ACF / PACF 시각화
fig, ax = plt.subplots(1,2, figsize=(14,4))
plot_acf(diffed, lags=30, ax=ax[0])
plot_pacf(diffed, lags=30, ax=ax[1])
plt.show()
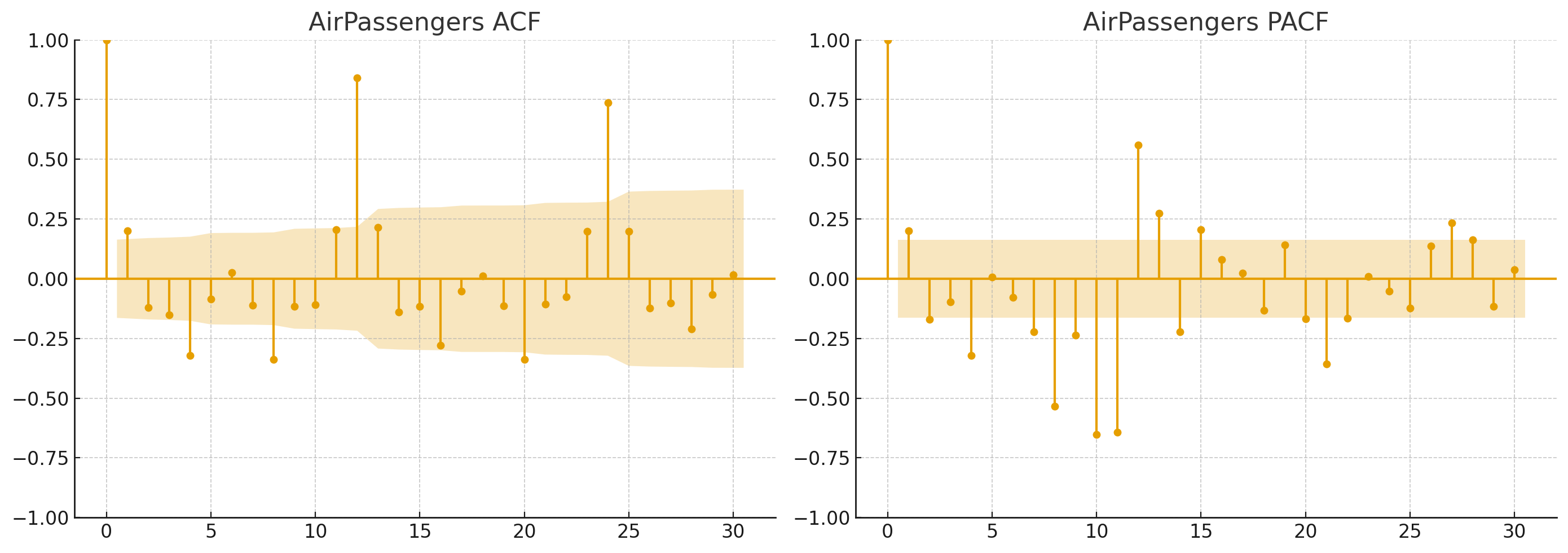
위 그래프의 노란 음영 부분은 신뢰구간을 의미하며, 이 구간 밖에 막대가 있는 경우 유의미한 자기상관이 있다고 판단할 수 있습니다.
먼저 ACF를 보면, Lag 1과 12가 뚜렷하게 신뢰구간 밖에 있음을 확인할 수 있습니다. 이어서 PACF를 보면, 이 또한 Lag 1과 12에서 유의미한 Lag를 포착할 수 있습니다.
이를 통해 p,q,d 를 추정해보면,
- PACF: Lag 1 이후 급격히 감소 > p = 1
- ACF: Lag 1 이후 급격히 감소 > q = 1
- 1차 차분으로 정상성 확보 > d = 1
결과적으로 ARIMA(1, 1, 1) 혹은 SARIMA(1, 1, 1, 12) 형태가 후보가 됩니다.
파라미터의 추정 - AutoARIMA
앞서 ACF/PACF를 통해 초기 파라미터를 추정했지만, 최적의 모형을 보장하기는 어렵습니다. 그래서 실제 추정 시에는 AutoARIMA(계절성이 있으면 (m=12) 등으로 SARIMA)를 사용해 AIC/BIC 기준으로 체계적으로 탐색합니다.
위에서 사용한 코드에 이어서 AutoARIMA 를 써보겠습니다. 이번에는 예측 후 시각화까지 진행해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import pmdarima as pm
# 예측 위해 train/test split (8:2)
train_size = int(len(log_transformed) * 0.8)
log_transformed_train = log_transformed.iloc[:train_size]
log_transformed_test = log_transformed.iloc[train_size:]
# autoARIMA
model = pm.AutoARIMA(
seasonal = True, # True인 경우, (p,d,q)에 m이 추가된 SARIMA 모델이 됨
m = 12, # 계절성(연간 주기)
suppress_warnings = True,
trace = True, # 파라미터 탐색 로그 출력
)
# 파라미터 탐색
res = model.fit(ap_transformed_train)
파라미터 탐색 로그가 출력되고, Best model: ARIMA(2,0,0)(0,1,1)[12] intercept 이와 유사하게 출력되면 완료입니다!
ARIMA 예측
그러면 이어서 예측 후 시각화까지 진행해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 테스트 구간 길이만큼 예측
n_test = log_transformed_test.shape[0]
preds, conf_int = res.predict(n_periods=n_test, return_conf_int=True)
# 시각화
x_axis = np.arange(log_transformed_train.shape[0] + n_test)
plt.figure(figsize=(10,4))
plt.plot(x_axis[:log_transformed_train.shape[0]], log_transformed_train.values, label="Train")
plt.plot(x_axis[log_transformed_train.shape[0]:], preds, label="Forecast")
plt.scatter(x_axis[log_transformed_train.shape[0]:], log_transformed_test.values, alpha=0.6, marker="o", label="Test (actual)")
plt.fill_between(x_axis[-n_test:], conf_int[:,0], conf_int[:,1], alpha=0.2)
plt.title("Log Transformed Air Passengers — AutoARIMA Forecast")
plt.legend()
plt.show()
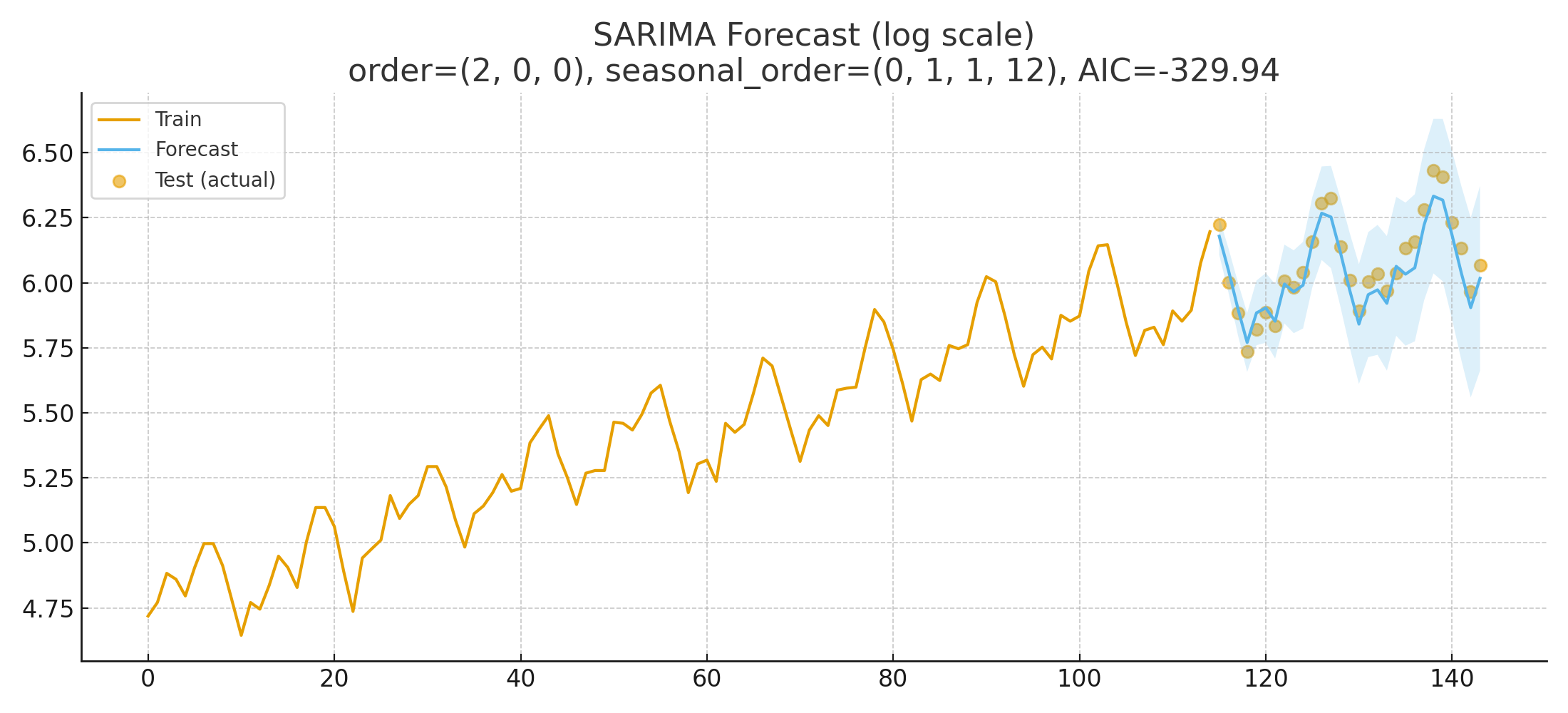
정확하진 않지만 얼추 유사하게 예측한 것을 확인할 수 있습니다. 다만 현재 예측은 log값이기 때문에 기존 값으로 변환하여 재확인합니다.
1
2
3
4
5
6
7
8
9
10
from sklearn.metrics import mean_squared_error
y_true = np.exp(log_transformed_test.values) # 실제 관측값 (exp 통해 역변환)
y_pred = np.exp(preds) # 예측값 (역변환)
# 평가 지표
rmse = mean_squared_error(y_true, y_pred, squared=False)
mape = (np.abs((y_true - y_pred) / y_true).mean()) * 100
print(f"RMSE: {rmse:.2f}, MAPE: {mape:.2f}%")
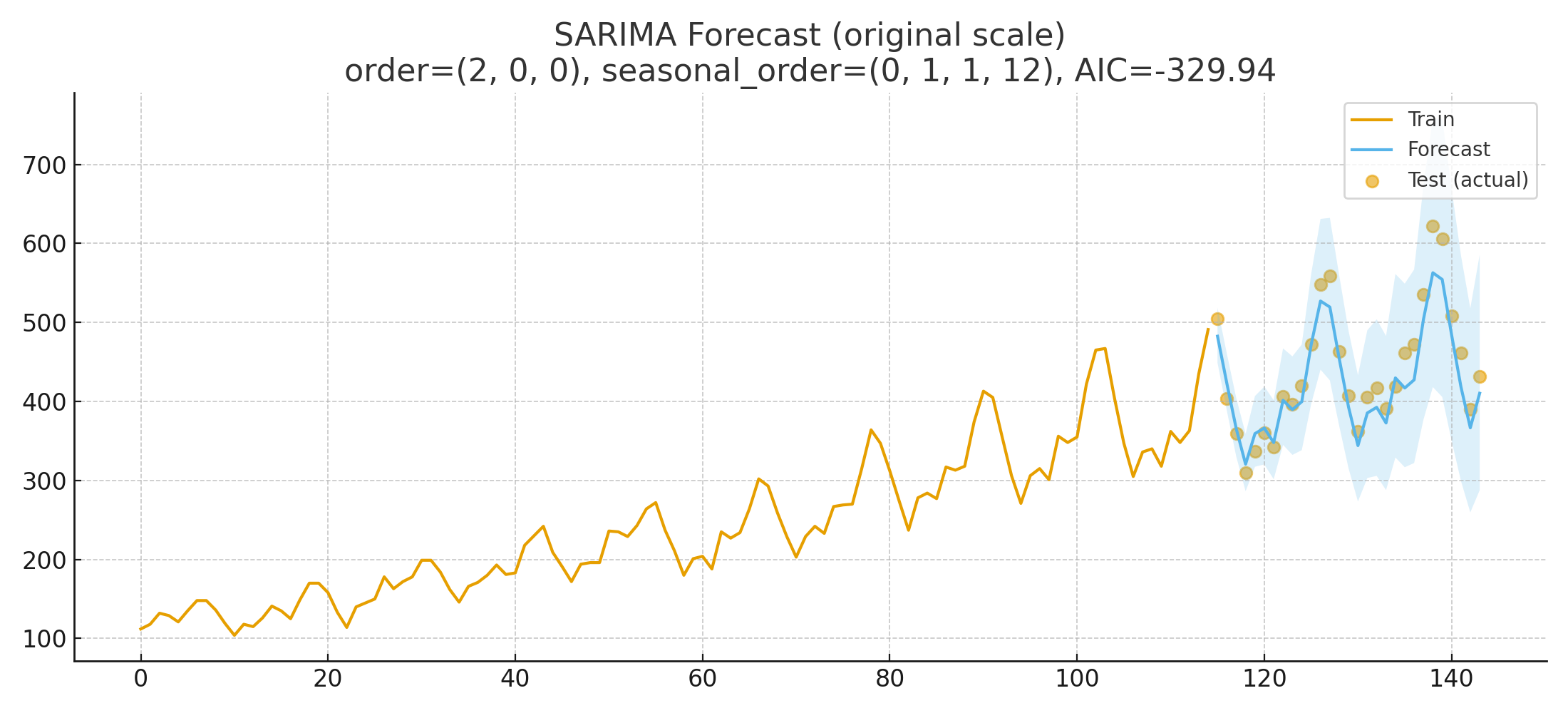
원 변환 이후에도 그럭저럭 괜찮은 성능을 확인할 수 있습니다.
이렇게 ARIMA 와 SARIMA 모델에 대해 알아보았습니다.
원래는 ARCH 와 GARCH 까지 알아보고자 했지만.. 분량이 너무 길어진 관계로 추가 포스팅으로 돌아오겠습니다.
감사합니다. 😊