[시계열 분석] 정상성과 전처리
안녕하세요, 행복한 휴가를 보냈더니 밀린 글이 많습니다… 머신러닝 관련 포스팅도 천천히 작성해보겠습니다.
이번 포스팅은 시계열(Time Series) 데이터를 처음 접하는 분들을 위한 내용이며, 1편과 2편으로 나누어져 있습니다.
1편에서는 정상성과 전처리를 다루고 있고, 2편에서는 모델링과 평가에 대해 설명할 예정입니다.
여유가 된다면 사례 분석도 진행해보겠습니다…
그럼 시작해보겠습니다!
1. 시계열 데이터란?
시계열 데이터는 시간의 흐름에 따라 기록된 데이터를 의미합니다.
주식 가격, 환율, 날씨, 교통량, 에너지 사용량 등 대부분의 데이터가 시계열적 성격을 가집니다.
시계열 데이터의 특징:
- 추세(Trend) : 장기적으로 증가/감소하는 방향성
- 계절성(Seasonality) : 정해진 일정 주기마다 반복되는 패턴
- 주기성(Cycle) : 정해지지 않은 기간으로 발생하는 상승/하락. 경기 변화 등 불규칙적인 반복
- 불규칙(Noise) : 모델로 예측 불가능한 요인
2. 정상성(Stationarity) 이란?
시계열 모델 대부분은 데이터가 정상성을 만족한다고 가정하고 설계합니다.
정상성을 만족하지 못하는 경우, 다양한 정제 작업을 통해 정상 데이터로 변환시키는 작업을 하는데요, 앞으로도 계속 언급될 정상성에 대해 알아보겠습니다.
정상성이란, 시계열의 통계적 특성이 시간에 따라 변하지 않는 것을 의미합니다. 좀 더 수리적으로 접근하면 아래처럼 정리해볼 수 있습니다.
정상 시계열의 조건
- 평균(Mean)이 시간에 따라 변하지 않음
- 분산(Variance)이 일정
- 자기공분산(Autocovariance)이 시차(Lag)에만 의존하고, 시점(Time)에는 의존하지 않음
즉, 쉽게 말해 “어느 시점을 끊어 데이터를 보더라도 분포가 안정적이다” 라는 것이 정상성의 핵심이라고 할 수 있습니다.
정상성은 왜 중요한가?
시계열 모델은 과거 어느 구간의 데이터의 관측 결과를 통해 미래 데이터의 값, 평균 혹은 분산의 변화를 예측하는 것을 목표로 하고 있습니다.
그런데 만약 데이터가 시간에 따라 평균과 분산이 변한다면(비정상 데이터라면), 모델이 학습한 규칙은 시간이 지남에 따라 무너져 버리게 됩니다.
즉, 모델이 신뢰할 수 있는 패턴을 포착하기 위해서는 정상성 확보가 필수적이라고 할 수 있겠습니다.
3. 정상성 진단
그렇다면 내가 보고있는 이 데이터가 정상 시계열인지, 비정상 시계열인지는 어떻게 확인할 수 있을까요?
시각화
가장 쉬운 방법은 눈으로 확인하는 것입니다.
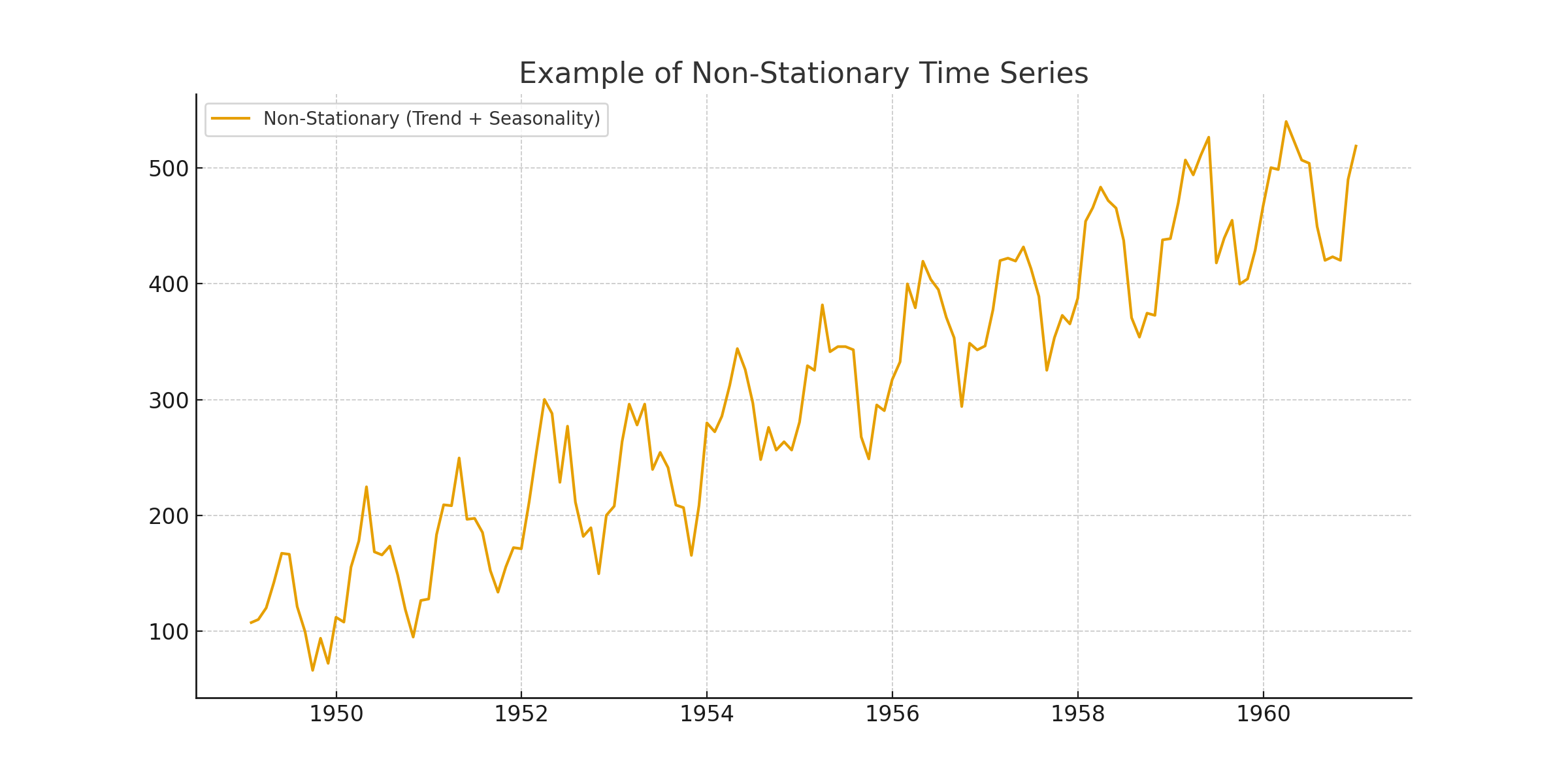
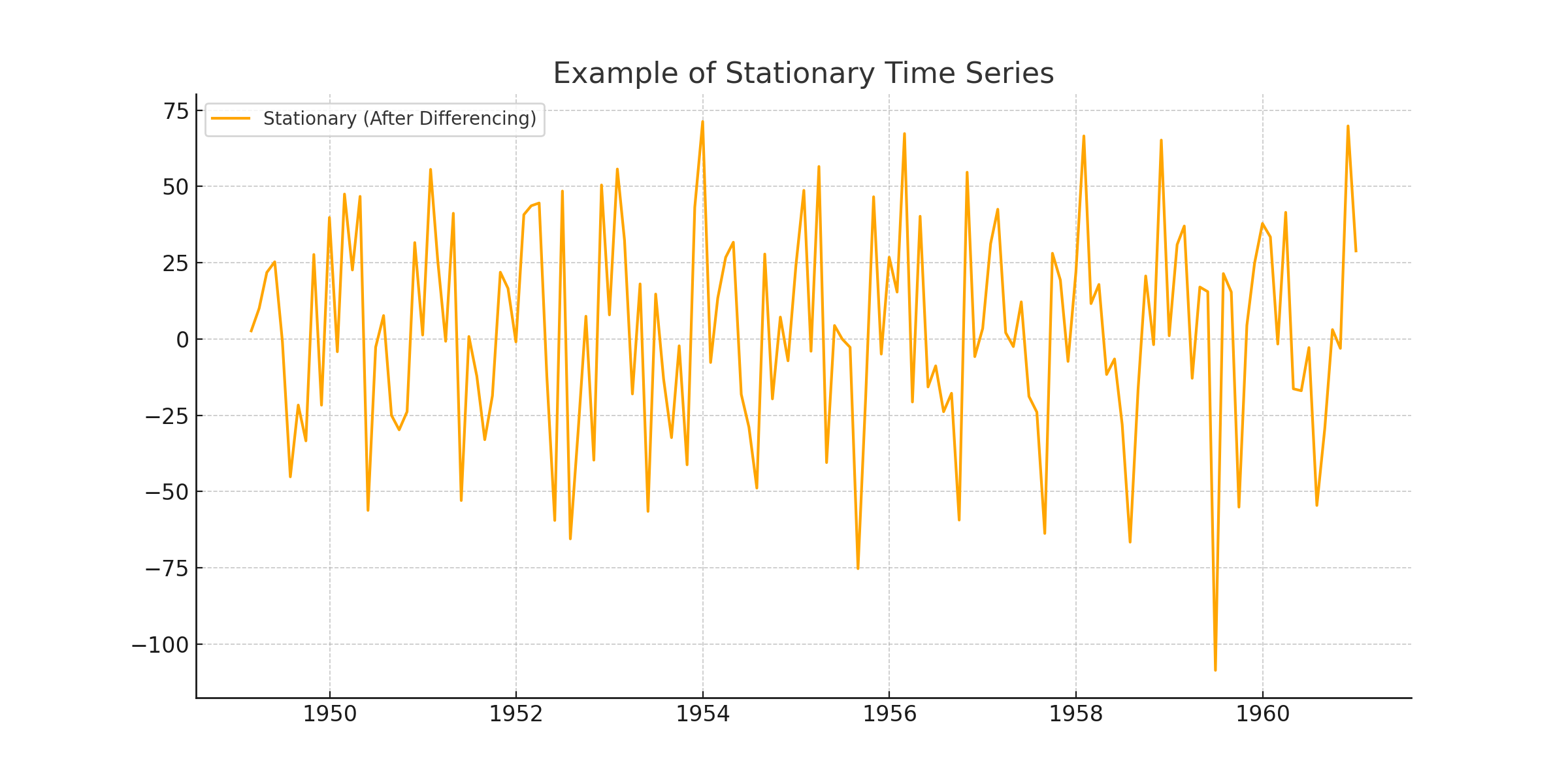
두 그래프는 시계열 데이터로 유명한 airline passengers 입니다.
위의 그래프는 전처리 없는 원본 데이터로, 시간이 흐를수록 수치가 커지고 있음을 알 수 있습니다. 즉 데이터 평균의 우상향 추세가 뚜렷하기에 정상성에 위배됩니다.
그러나 차분 처리를 한 아래의 데이터를 보면, 평균이 거의 일정해졌음을 알 수 있는데요, 이러한 경우 정상 시계열로 변환되었다고 할 수 있습니다.
이처럼 그래프를 보면 어느 정도 정상성 여부를 감 잡을 수 있지만, 시각화만으로는 설득력이 부족합니다.
이를 보완하기 위해 우리는 단위근(Unit Root) 검정이라는 통계적 방법을 사용합니다.
대표적으로 많이 쓰이는 검정으로 ADF와 KPSS 두 가지 방법이 있습니다.
ADF Test (Augmented Dickey-Fuller)
- 귀무가설(H₀): 단위근이 존재한다 → 비정상 시계열이다.
- 대립가설(H₁): 단위근이 존재하지 않는다 → 정상 시계열이다.
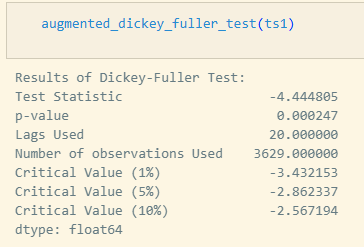
p-value가 거의 0에 가까움을 알 수 있는데요, 이를 통해 귀무가설을 기각하고 정상 시계열 데이터라고 해석할 수 있습니다.
KPSS Test (Kwiatkowski-Phillips-Schmidt-Shin)
- 귀무가설(H₀): 정상 시계열이다.
- 대립가설(H₁): 비정상 시계열이다.
Note: KPSS Test는 ADF Test와 반대로 귀무가설에 ‘정상 시계열이다’를 가정합니다.
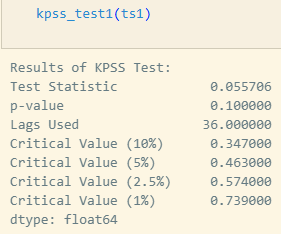
p-value가 0.1로 출력되어 있습니다. (statsmodels의 kpss 함수는 p-value를 0.1까지만 계산해서 보여주고 그 이상은 전부 0.1로 표시합니다)
즉, 일반적으로 사용되는 95% 유의수준(α = 0.05) 기준에서 봤을 때, 현재 p-value는 0.1이므로 귀무가설을 기각할 근거가 없으므로 정상 시계열 데이터라고 해석할 수 있습니다.
이처럼 시각화, ADF, KPSS 모두 활용하면 보다 안정적으로 정상성 여부를 검토할 수 있습니다.
4. 정상화 기법
검토 결과, 비정상 데이터라고 판단했습니다. 그렇다면 정상 시계열로 변환하는 방법으로는 어떤 것들이 있을까요?
여기서는 유명 시계열 데이터 Airpassengers 를 활용해보겠습니다.
Note: 위 데이터는 Box, Jenkins, and Reinsel (1976), “Time Series Analysis: Forecasting and Control” 의 공개 시계열 데이터입니다
(1) 분산 안정화: 로그 변환
데이터의 분산이 시간이 지남에 따라 증가할 경우, 로그 변환으로 안정화할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ap = pd.read_csv("airline-passengers.csv")
ap.drop('Month', axis = 1, inplace = True)
plt.figure()
plt.plot(ap) # 원본 데이터 시각화
plt.show()
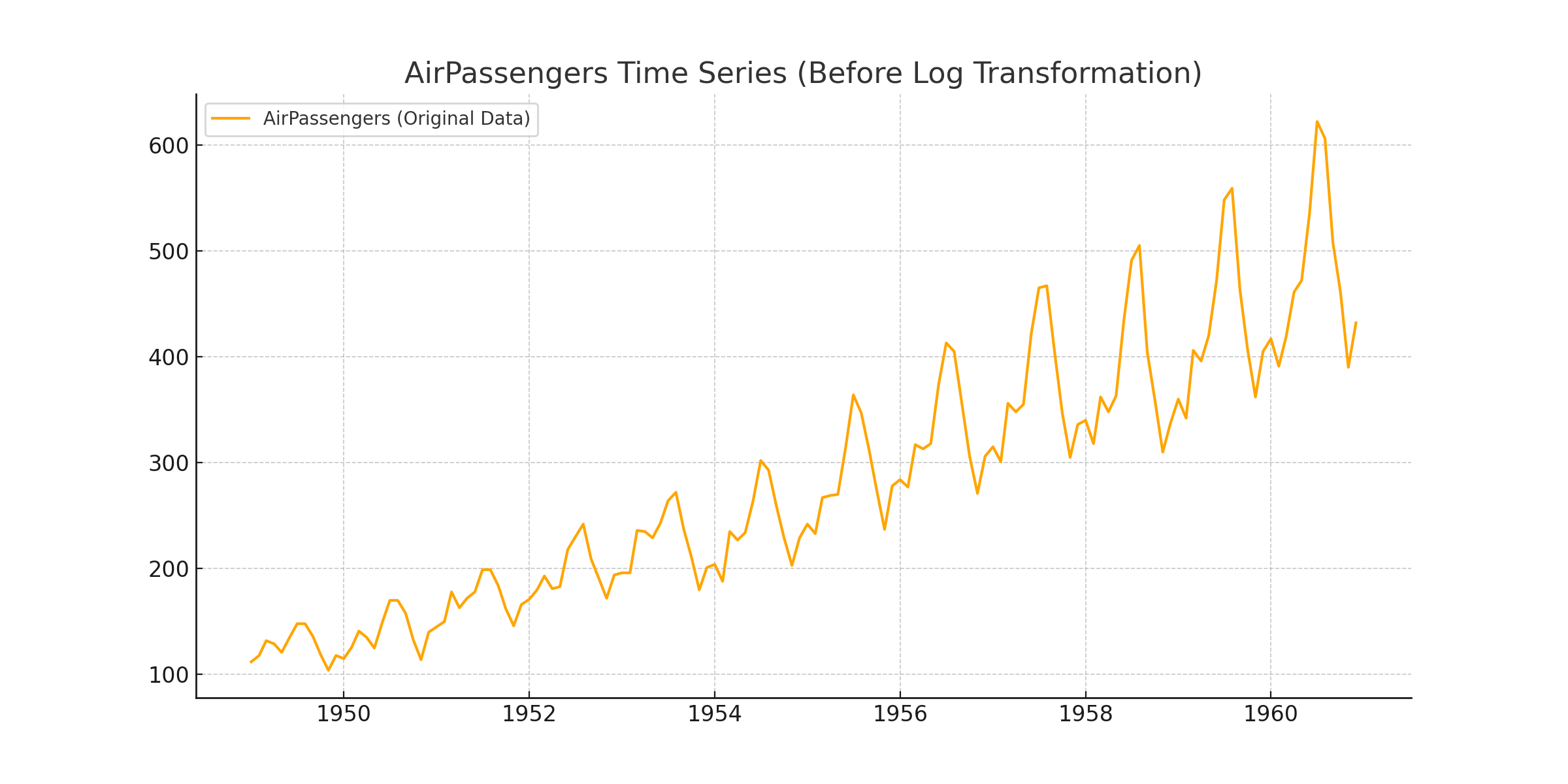
기존 데이터는 시간이 지날수록 분산이 커지고 있음을 알 수 있습니다. 이러한 분산을 안정화 시키기 위해 로그 변환을 진행합니다.
1
2
3
4
5
log_transformed = np.log(ap) # 로그 변환
plt.figure()
plt.plot(log_transformed) # 로그 변환 데이터 시각화
plt.show()
로그 변환 이후 분산이 매우 안정화되었습니다. 그러나 전체적으로 평균이 증가하는 우상향 추세는 남아있습니다.
이를 제거하기 위해서 차분을 진행합니다.
(2) 추세 제거: 차분(Differencing)
데이터에서 이전 시점 값을 빼서 추세를 제거합니다.
1
2
3
4
5
diffed = log_transformed.diff()[1:] # 1차 차분 시 첫 번째 index는 NaN이 되므로, [1:]
plt.figure()
plt.plot(diffed) # 차분 데이터 시각화
plt.show()
최종적으로 추세도 제거된 (시각적으로 봤을 때) 정상 시계열 데이터를 얻을 수 있습니다.
이후 ADF, KPSS Test를 진행하여 정상성을 확인합니다. 만약 비정상 데이터로 검정될 경우, 계절성을 의심해봐야 합니다.
(3) 계절성 제거: 계절 차분
시계열 데이터의 특성 상, 월(month) 혹은 연간 주기로 반복되는 패턴을 갖는 경우가 많습니다.
airpassengers data의 경우, 1년 주기의 계절성을 갖는 데이터이므로, 이어 계절성을 제거합니다.
1
2
3
4
5
6
7
seasonally_diffed = diffed.diff(12)
seasonally_diffed.dropna(inplace = True) # 계절 차분의 경우 Null 값이 12개 발생하므로 dropna
seasonally_diffed
plt.figure()
plt.plot(seasonally_diffed)
plt.show()
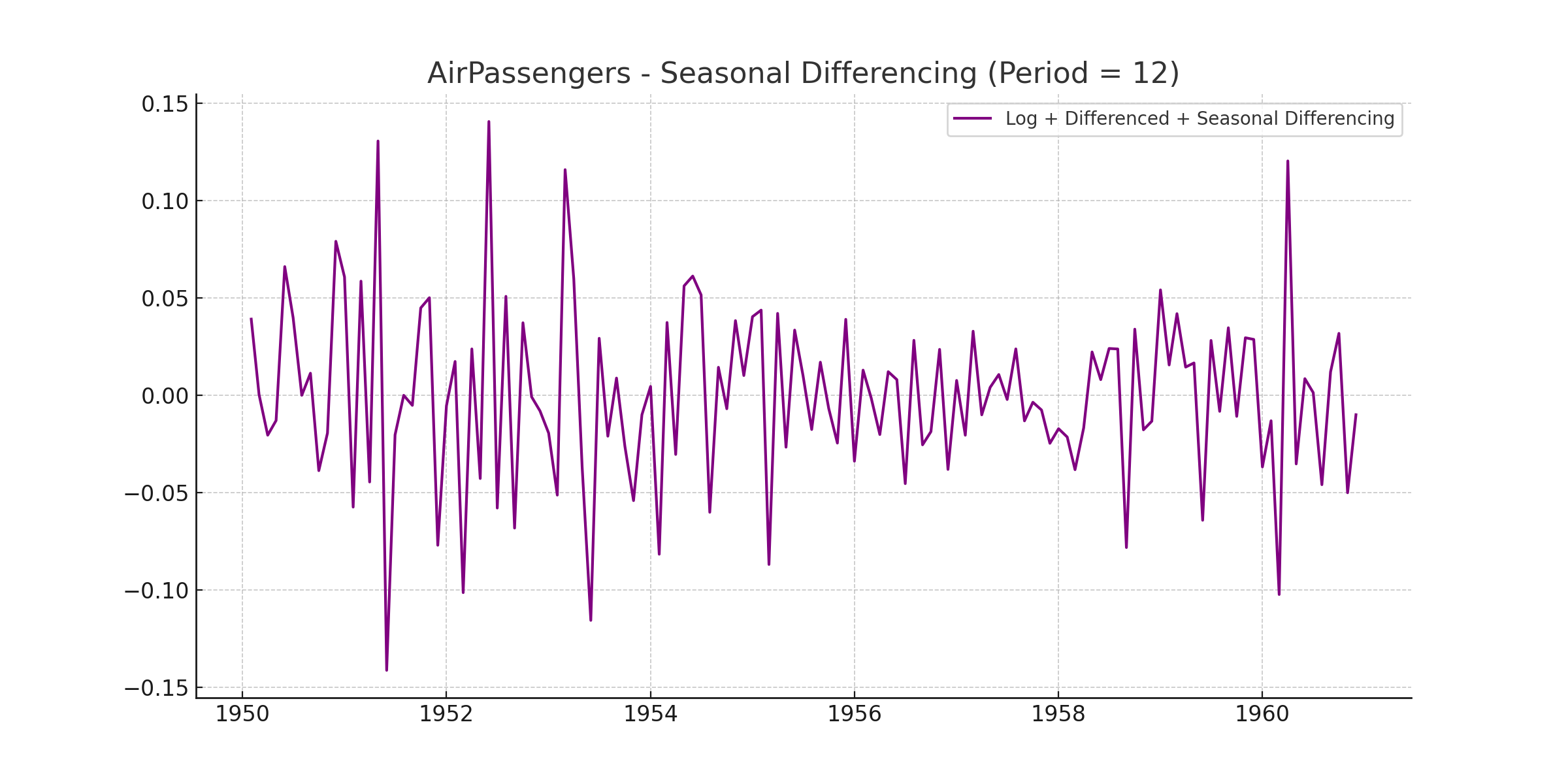
눈으로 보기엔 이전보다 훨씬 복잡하고 이상해보이지만, 이것이 저희가 ADF와 KPSS 같은 Test를 진행하는 이유입니다.
이전 데이터에는 추세와 계절성 특성이 남아있었기 때문에 규칙적으로 보였던 것이고, 현재 데이터는 백색 잡음에 가깝다고 할 수 있습니다.
Note: 백색 잡음(White Noise)란, 시계열의 가장 단순한 정상성 형태를 의미합니다. 평균과 분산이 일정하고 자기상관성이 없는 형태를 의미합니다.
여기까지 시계열 데이터의 정상성 확인 및 전처리를 알아보았습니다.
정상성 확보는 단순한 데이터 전처리라고 하기 보다는, 시계열 모델링의 출발점이라 할 수 있으니 매우 중요합니다.
다음 포스팅에서는 이렇게 정제된 데이터를 활용하여 예측 모델을 알아보도록 하겠습니다.
감사합니다. 😊